[引擎解包/封包攻略] yu-ris 引擎简单分析

xdm新年快乐 老摸鱼人又来啦
这次整的是一个叫做yu-ris的引擎,是比较老的版本,分析起来还算顺利
这个引擎还是比较常见的,其封包扩展名为“ypf”,各位L$P应该都很眼熟了
一、封包
主程序拖到IDA直接搜索“YPF”字符串即可找到加载封包的地方。
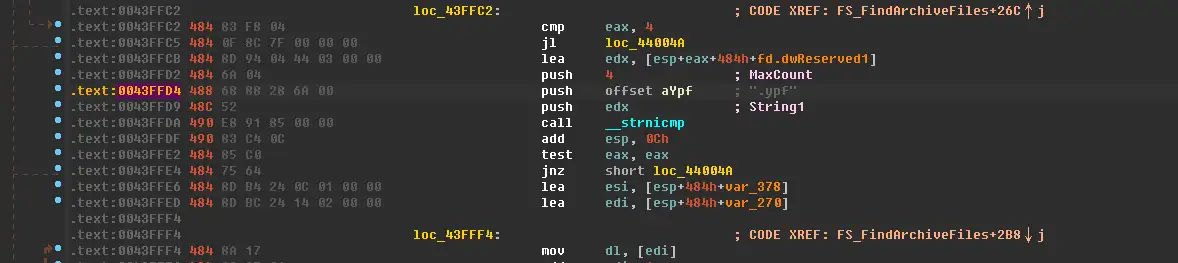
直接F5反编译这个函数,这个函数是在游戏目录里搜索所有“ypf”文件,并把文件名存储到数组里。
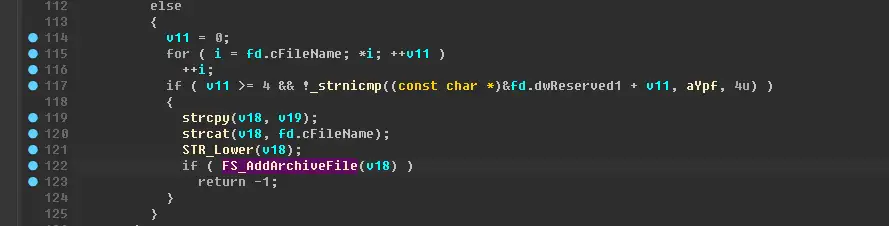
可以看到文件名被存储到gArcFilePath这个数组里,然后下面打开了封包,并读取了文件头部的几个数据,再往下就没有任何处理了,所以这个函数只是记录一下封包的文件的信息而已,真正读取封包的代码不在这里。
但可以顺藤摸瓜,找到引用了gArcFilePath的函数,

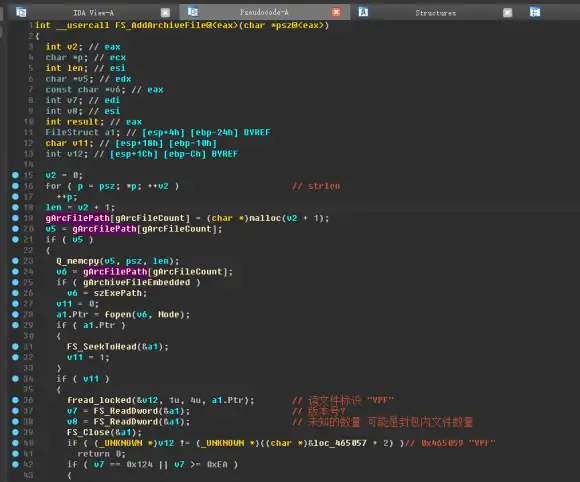
转到这个函数看看
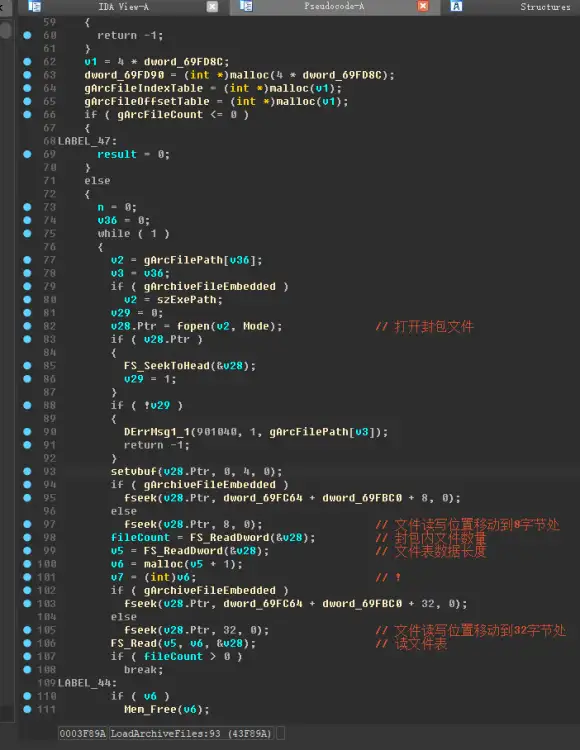
这里可以看到,此处调用fopen打开了封包文件,并读取了文件头和文件表数据。再往下看,是解析文件表数据的代码。

顺序解析文件表,并把文件表里的文件信息全部存储到数组里。这里实际上只保存了封包中某文件的信息在该封包文件表中的偏移量,并且解密了一下文件名,做了个判断,所以这个函数实际上也还是只读取了文件信息,但是可以看到它把偏移量存到了一个数组里,说明这个偏移量肯定会在真正读取封包内文件的时候被用到,所以直接找这个数组的引用。

来到FS_FindResInArchives这个函数里
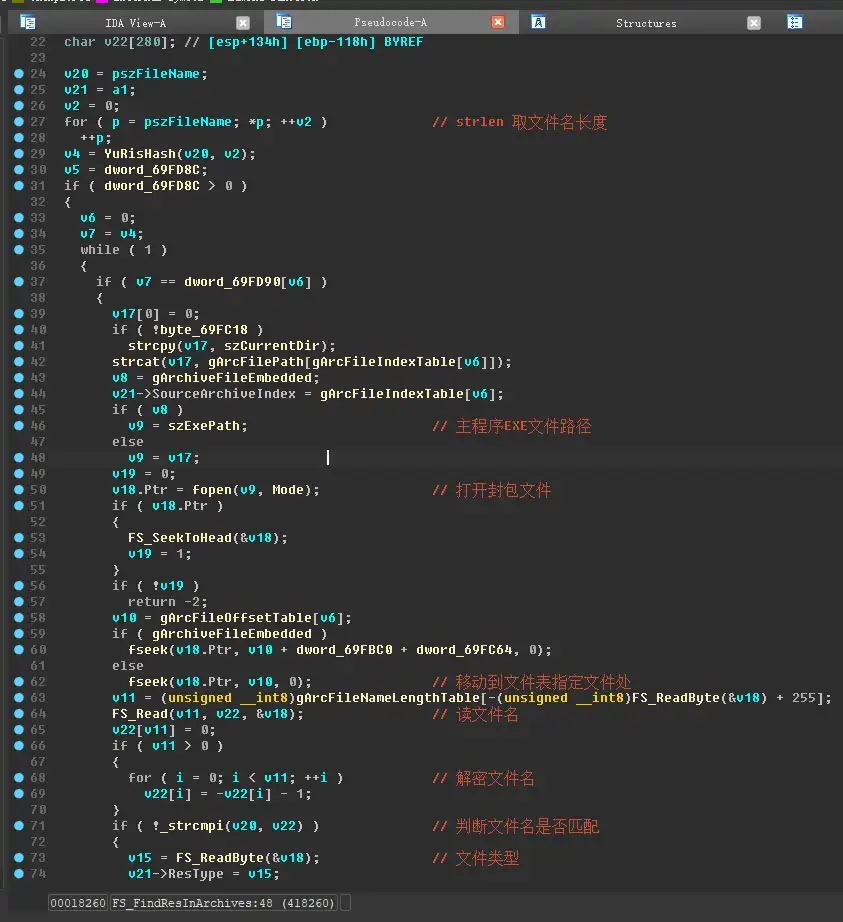
首先计算文件名(文件路径)的HASH值,然后通过这个HASH值从刚才已经加载的封包文件信息中搜索该文件。这样可以加快文件搜索速度,是必备的优化。

函数的最后,如果成功在封包内找到了该文件,就把其索引(ID)保存下来,返回。
很显然,这个函数只负责在封包内搜索文件,那么调用它的代码一定是想通过它来加载一个封包内的文件。
所以接着找引用了它的代码。
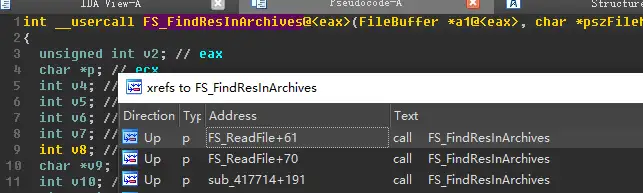
可以看到FS_ReadFile这个函数,调用了它。
一、封包(2)
转到FS_ReadFile函数,可以看到它调用了几个函数来搜索文件。

如果成功找到了文件,那么v9(即文件ID)必然不为零。
再往下,看到了一个switch结构,条件是 SourceType ,这个 SourceType 表示该文件来自哪里。
例如:文件夹、封包、编译器。。等等
这里只关心来自封包内的文件,其值是2,上面FS_FindResInArchives函数的最后面设置的。
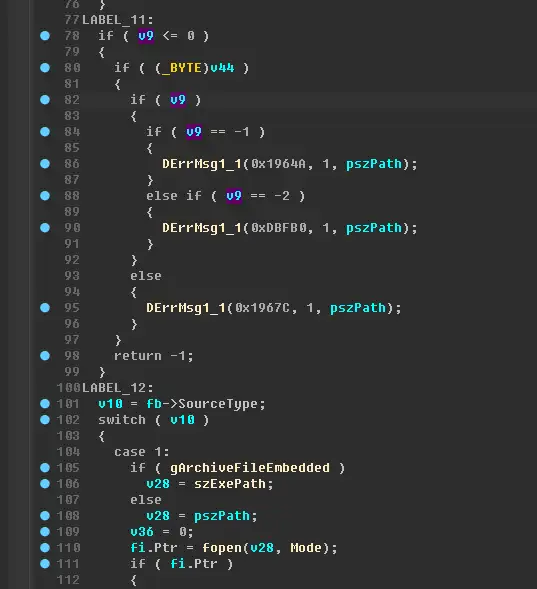
转到case 2查看代码:
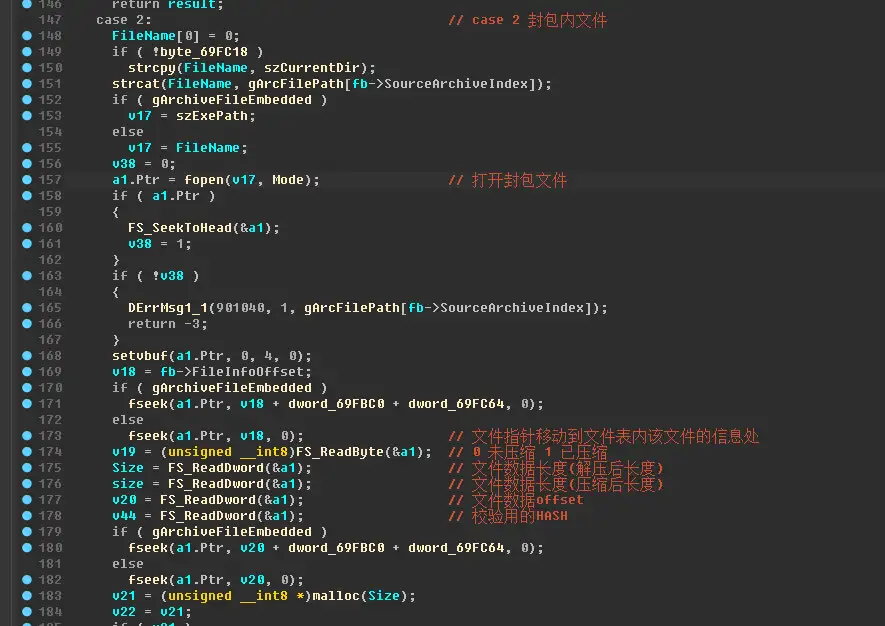
此处再次打开封包文件,然后把读写指针移动到FileInfoOffset处。FileInfoOffset也是在FS_FindResInArchives里设置的。
然后读取了目标文件的基本信息,是否压缩,文件数据长度,校验值等等。。
再往下就是真正读取文件数据的地方了,
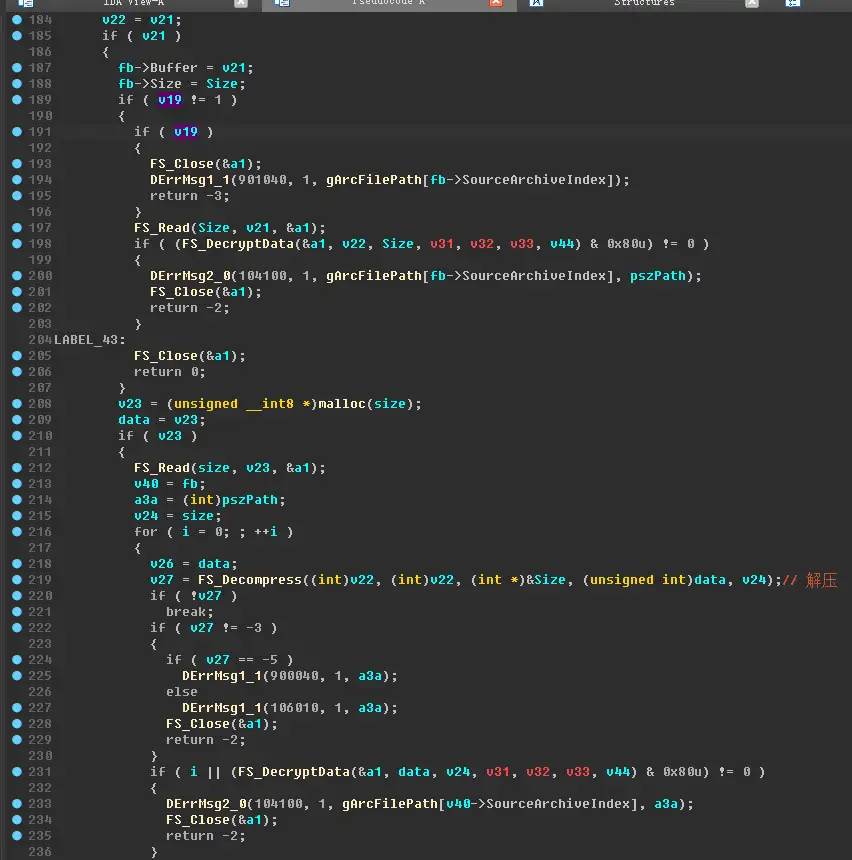
如果文件数据没有被压缩,则读取后,校验数据,然后进行解密,然后再校验解密后的文件数据,如果一切顺利,则返回成功。
如果文件数据被压缩,则先进行解压再进行解密。
先说解密算法,该算法也是简单的按块查表异或,表则存储在文件数据的后面,所以FS_DecryptData里面还会读取一段数据,该数据就是异或用的表。
解压算法,根据特征可以推断为zlib的deflate,此处就不展开说了。
从 FS_ReadFile 函数出来之后,一个封包内的文件就已经读取完成了。
二、脚本(2)
文件:yst.ybn【YSTD文件】
该文件只存储了一个简单的count,用于定义yu-ris虚拟机中数据寄存器的数量。
关于数据寄存器的解释:
在yu-ris中,数据寄存器的实现为:

虚拟机指令想要将数据存储到数据寄存器中,则需要两个ID,代码如下:
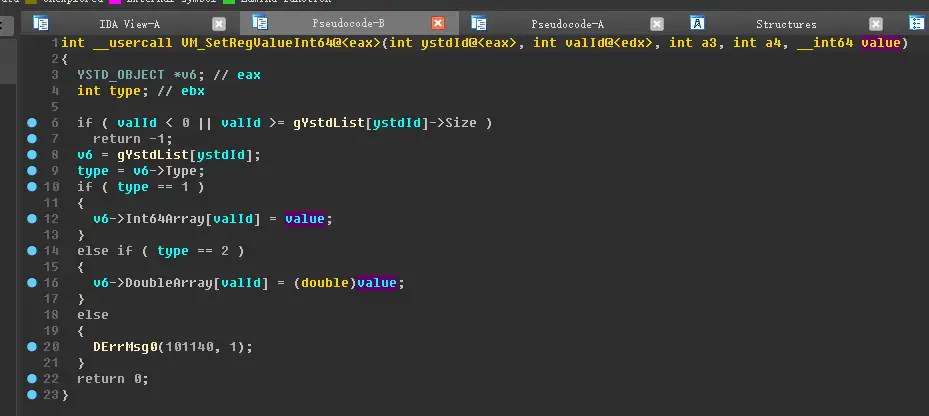
我简单将其命名为:ystd_Id, val_Id
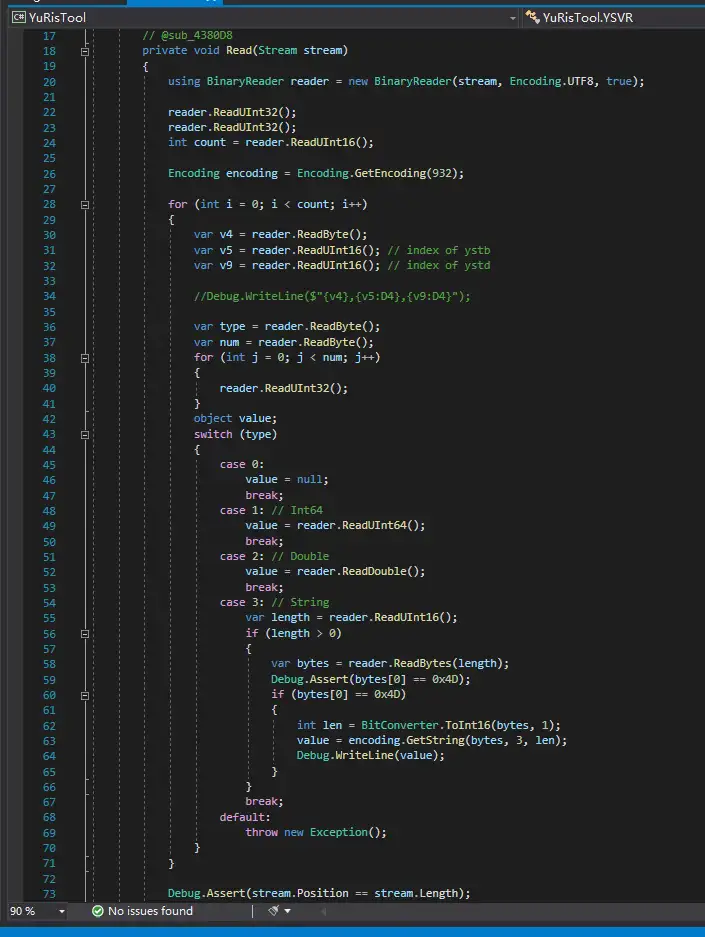
文件:ysv.ybn 存储了yu-ris虚拟机中数据寄存器的容量和初始值
容量即上图中****Array的大小
文件:yst_list.ybn
该文件存储了yst脚本的源文件名,对应yst*****.ybn文件
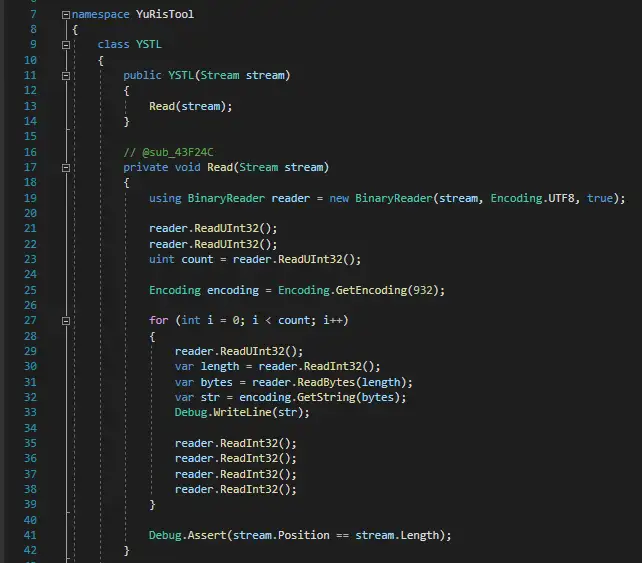
这些源文件名也是调试脚本用的。
二、脚本(3)
文件:yst*****.ybn
这些文件则是每个yst脚本编译后产生的二进制代码文件。
里面的内容即是游戏的内容。
在IDA中搜索 "yst%05d.ybn" 即可快速转到加载代码。
大致看一下加载过程:

重写之后:
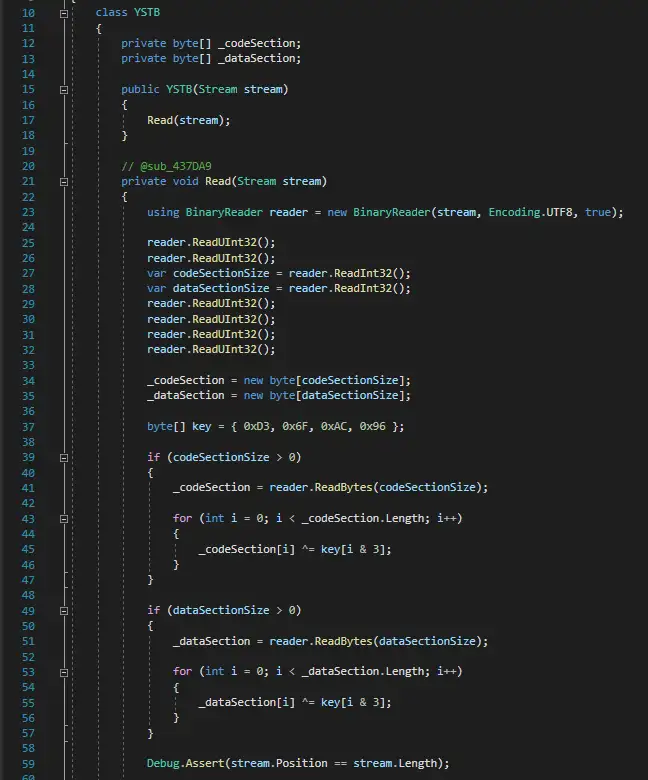
可以看到这是经典的代码文件格式,包含两个Section(区段),CodeSection是编译脚本得到的二进制指令码
DataSection是脚本中的指令所使用到的参数值或者参数字符串的数据
此外每个Section都是加密的,需要进行解密。
解密用到的key可以简单在主程序中找到


将一个字符串输入到YuRisHash函数中,即可得到Key。然后将字节序反转即可。
下一节解释 Yu-ris 虚拟机指令的执行过程
三、虚拟机
虚拟机的执行从这个函数开始:

该函数很清晰地展示了虚拟机的初始化流程
1、加载虚拟机相关的环境数据
2、找到入口点
3、设置虚拟机EIP到入口点
如果虚拟机初始化失败,则退出游戏。

初始化完虚拟机和其它声音设备之类的东西后,引擎就初始化完成了。
接下来就会进入游戏主循环,开始真正执行虚拟机代码,和刷新窗口

进入 Engine_Update函数:
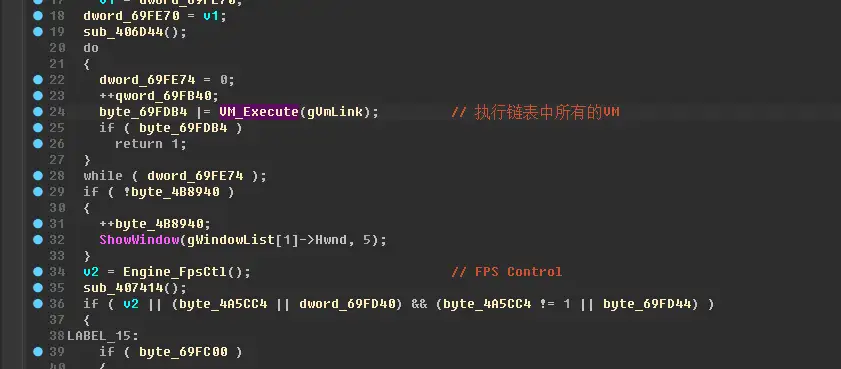
这里调用了VM_Execute函数,跟进:
忽略掉其它代码,重点在这里。
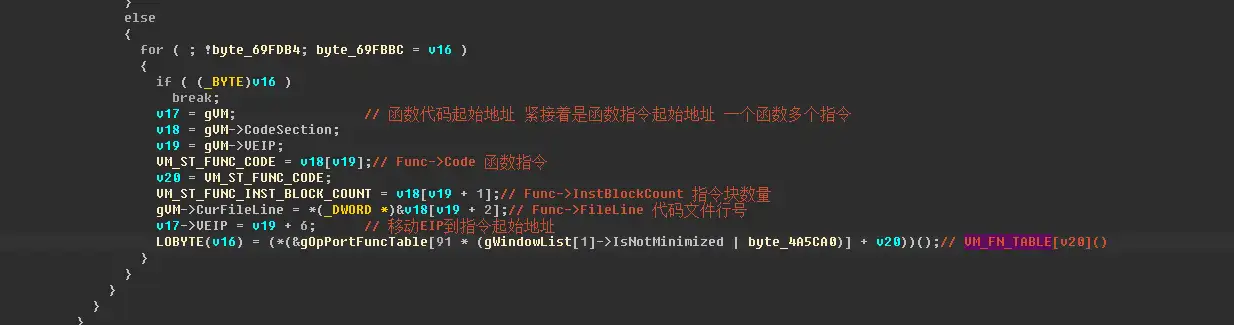
这里就是解析虚拟机指令的地方了。
可以看到代码从CodeSection中读取指令代码,并调用对应的函数。
将其整理出来后就是这样:
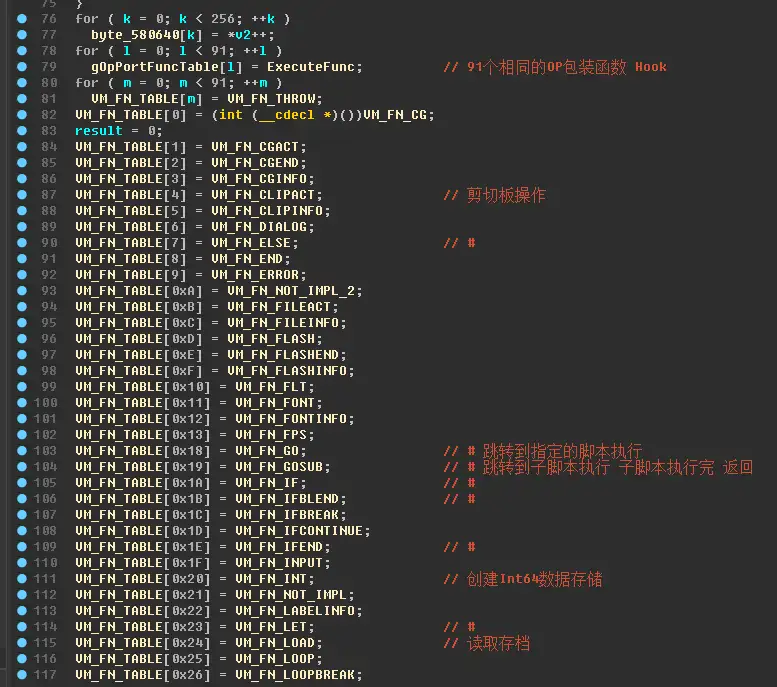
虚拟机指令从一个function code开始(其实是label),第一个字节是function码,对应了 VM_FN_TABLE 中的每一个函数,写为:VM_FN_TABLE[ funcCode ] ( ) 执行虚拟机代码处理函数
第二个字节是函数指令块的数量,为什么是指令块的数量,而不是指令的数量呢。因为yu-ris虚拟机里,有一些function的指令大小并不是按照这个count来算大小的,所以严格来说应该是指令块的数量,因为指令块的大小是固定的,每个块12字节。
查找 VM_FN_TABLE 的引用,可以找到这个函数。这里就是初始化虚拟机指令处理函数的地方。
三、虚拟机(2)
虚拟机指令处理函数。
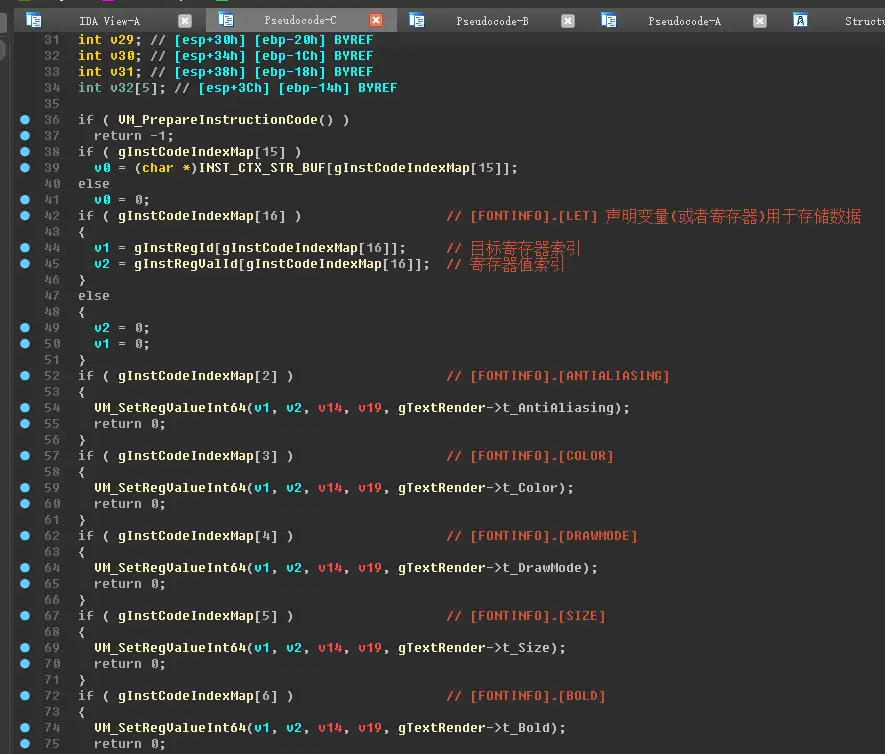
我们找一个结构清晰一点的函数作为例子,例如 VM_FN_FONTINFO
该指令让yst脚本可以获取字体相关的信息。
先进去看 VM_PrepareInstructionCode 这个函数:
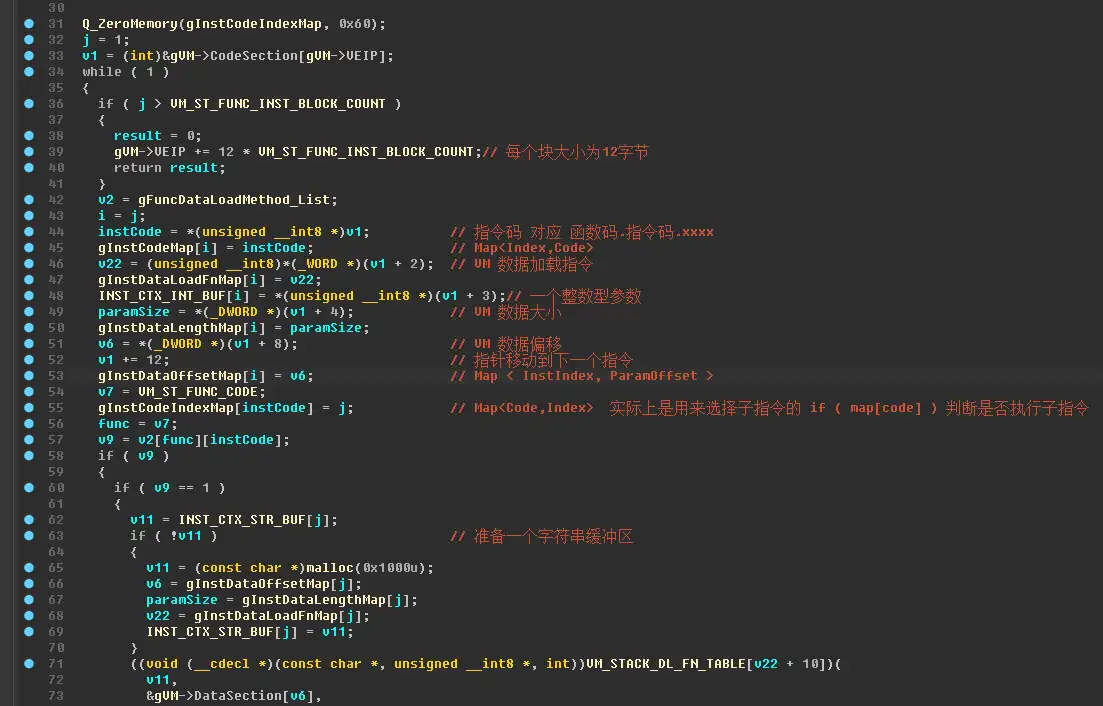
这个函数里有一个循环,解析了一个虚拟机函数中的所有指令。
这个循环里,将每个指令:是否执行、所需参数、所需数据,等相关信息都存储到了数组里。
gInstDataOffsetMap[ ] 指令所需的数据在DataSection中的偏移量
gInstDataLengthMap[ ] 指令所需的数据的长度
INST_CTX_INT_BUF[ ] 指令的一个简单整型参数
INST_CTX_DBL_BUF[ ] 指令的int64型参数
INST_CTX_STR_BUF[ ] 指令的字符串型参数
等等。
此外,加载指令参数,还需要通过一系列函数进行加载,而不是简单的读取数据。
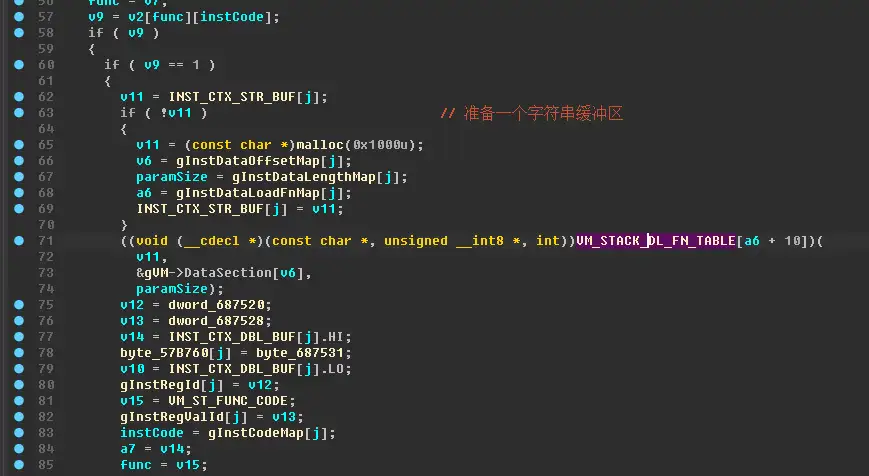
指令可以指定任意一种方式加载参数。
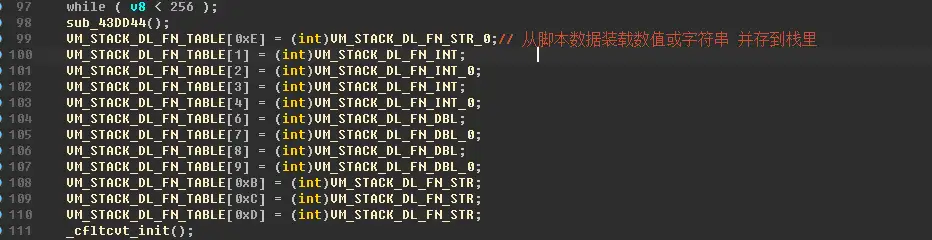
例如,加载一个字符串型的参数
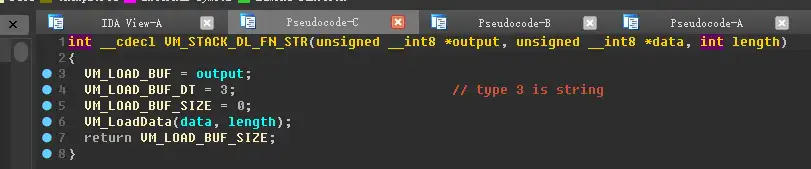
跟进VM_LoadData
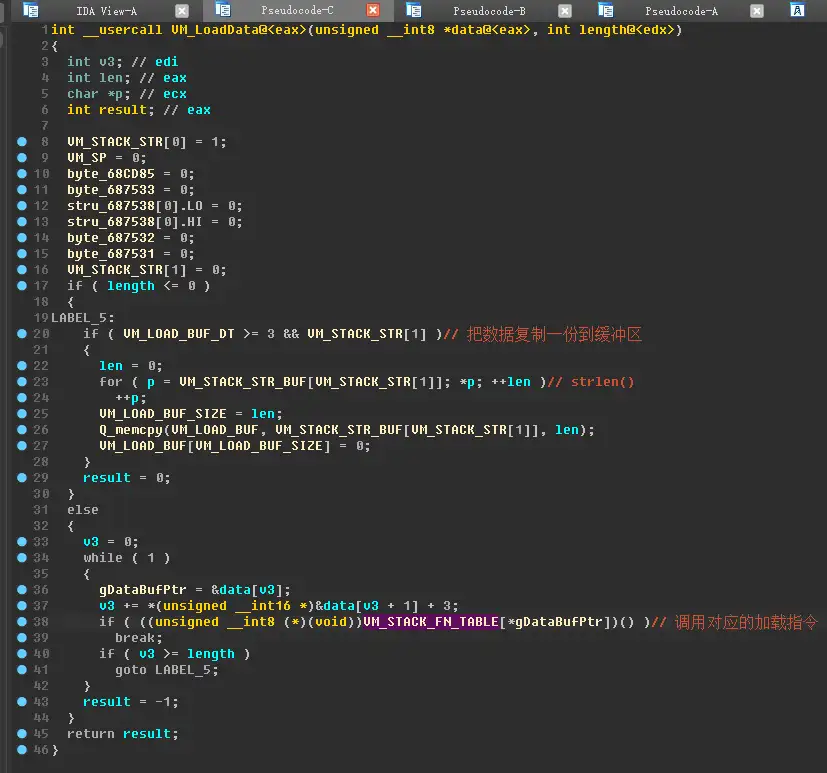
其中,gDataPtr就是上面的 gInstDataOffsetMap[ j ] 指定该参数的数据在DataSection中的偏移量
数据长度 length 同理。
此外还可以看到,VM_LoadData 加载数据,实际上调用了VM_STACK_FN_TABLE里的函数,
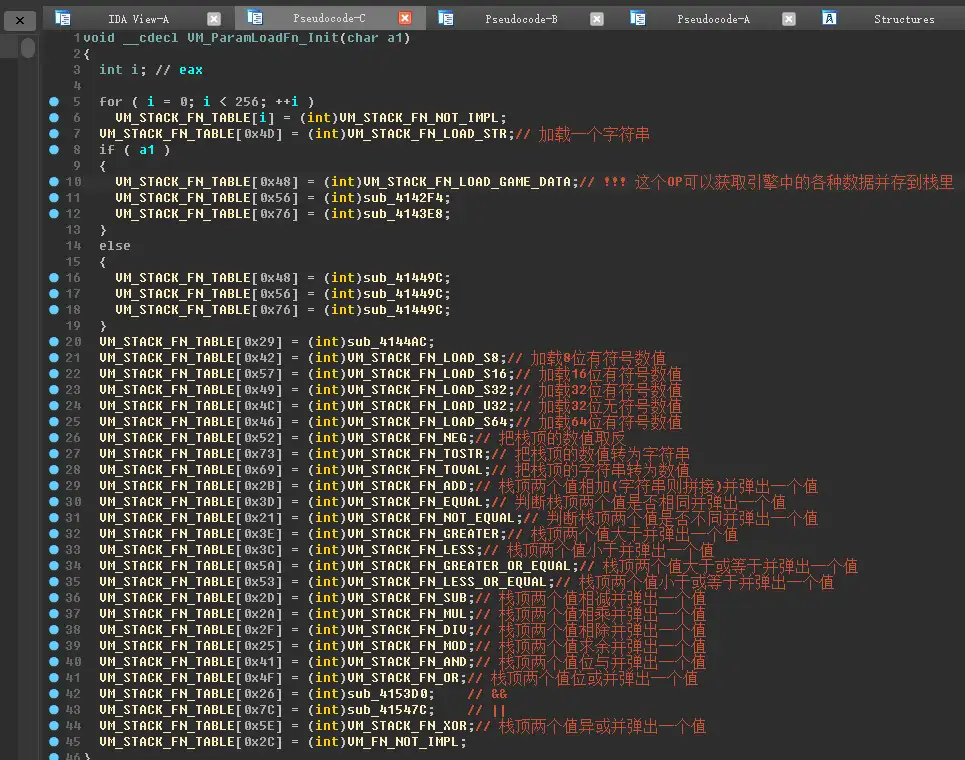
并且,VM_LoadData 是在循环里调用 这些函数的,也就是说,当加载一个指令的参数时,不仅可以直接加载数值或者字符串,还可以在加载后进行一些计算和判断,并且这些Load函数中,有一些是获取引擎当前的数据的。
这个参数加载的处理,可以说挺花哨的了。加载一个64位数值到虚拟机栈里。
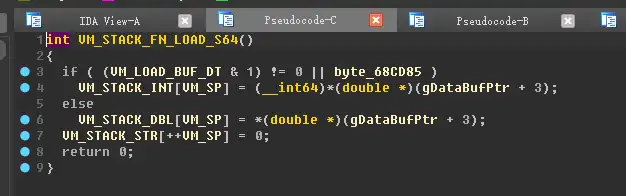
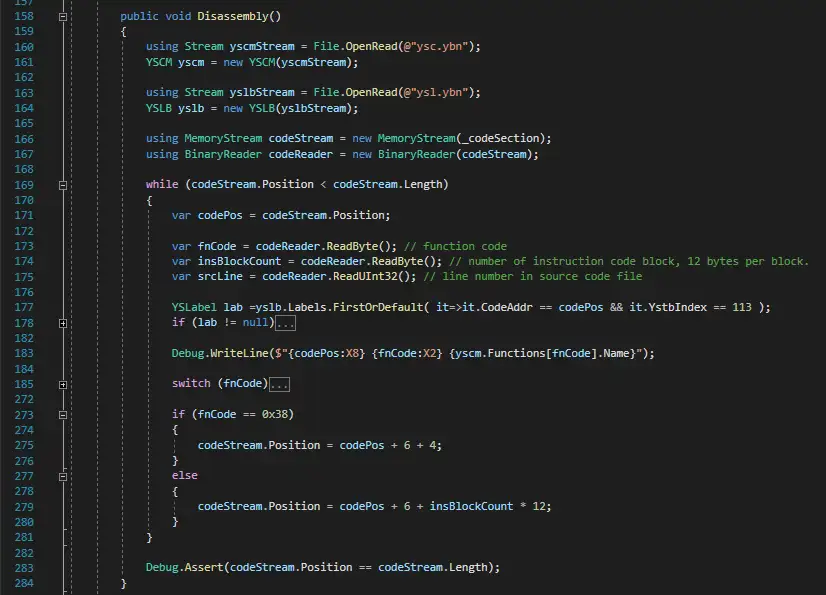
以下是简单反汇编的脚本,其中只包含了虚拟机函数和其函数指令,没有包含指令数据加载的反汇编。
可以看到还是勉强能看到一个执行流程的

三、虚拟机(3)
回到 VM_FN_FONTINFO 函数,调用了 VM_PrepareInstructionCode 之后,所有指令的数据都已经准备好了。

首先通过 if ( gInstCodeIndexMap[16] ) 这样的条件,来判断 是否要执行函数中的某一个指令。
例如此处,先判断是否要执行 FONTINFO.LET 指令,该指令设置数据寄存器的 ystd_Id 和 val_Id 用于存储数据
然后接着 if ( gInstCodeIndexMap[3] ) 判断是否要执行 FONTINFO.COLOR 指令,该指令获取引擎中字体的信息:字体颜色。如果执行该指令,则将引擎字体颜色的值存储到之前 LET 指令设置的数据寄存器中。
yu-ris 中大部分指令都按照这个流程执行。当然其中有一些例外,有些函数是没有子指令的,单纯就是用来执行一个引擎的函数。或者直接不进行任何处理。
四、游戏文本
想要拿到文本,首先肯定得知道文本在哪个文件里。
包含游戏文本的脚本文件通常都不会很小,少说都有个一百两百KB的。
然后我瞄上了 yst00113.ybn 这个文件(其它游戏可能不同)用上面的反汇编代码直接一顿操作,得到如下结果:

可以看到这个脚本里有一堆 0x54 和 0x4F 指令(函数)先看 0x54 函数
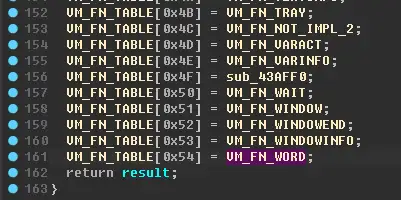
跟进去看看:

可以看到里面有个醒目的 Q_memcpy 从 DataSection 里复制了一段数据到某个缓冲区里。那么我们直接上x64dbg看看这段数据是啥。
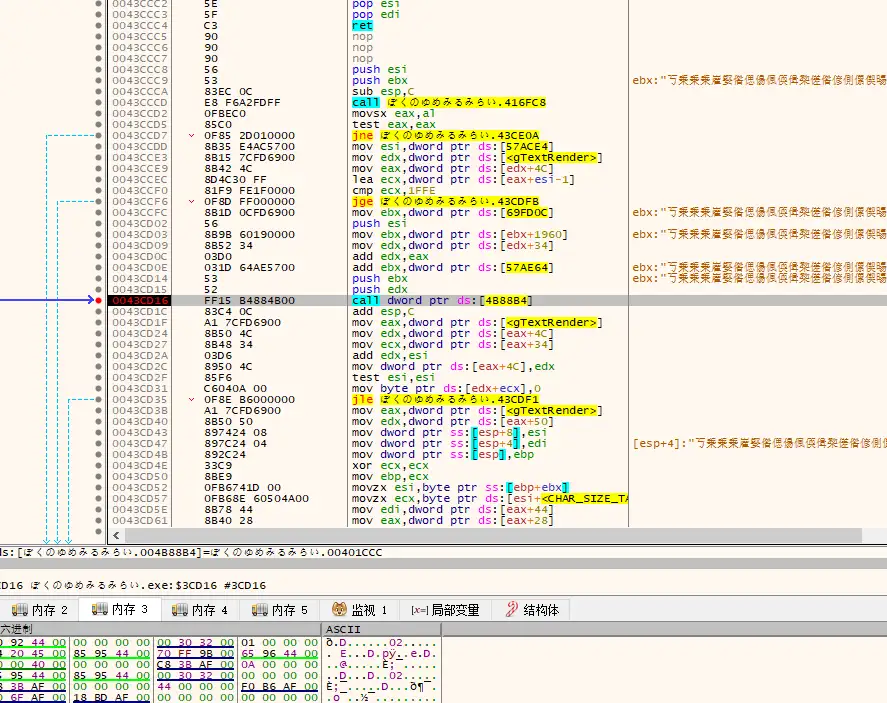
根据反汇编看,Q_memcpy的第二个参数是_Src,也就是源数据的内存地址,这里是 push ebx 所以我们在内存窗口中查看一下ebx中的内存地址指向的内存数据是啥。

没错,正是游戏文本。
那么我们想要拿到游戏文本,只需要解析这个 yst00113.ybn 里的 0x54 指令就好了。按照之前解析虚拟机代码的格式解析完整个脚本:
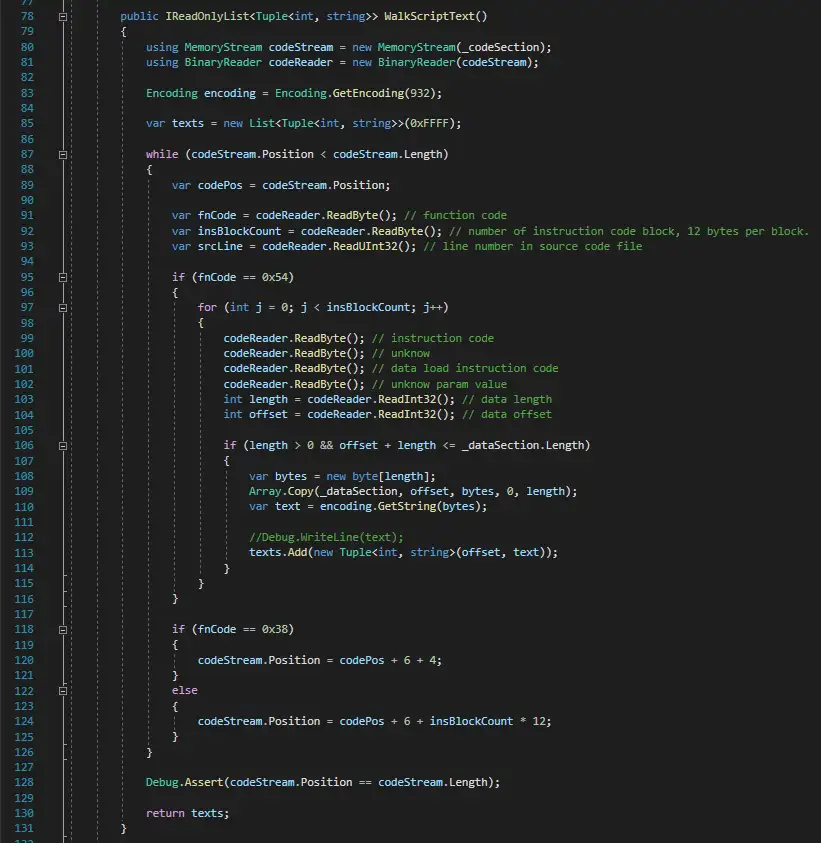
读取脚本中的所有函数指令,如果遇到0x54就进行解析。
读取到dataOffset和dataLength之后,就去DataSection里把数据复制出来。
然后用日文编码(cp932)解析文本,解析成C#字符串。然后写出文本文件即可。
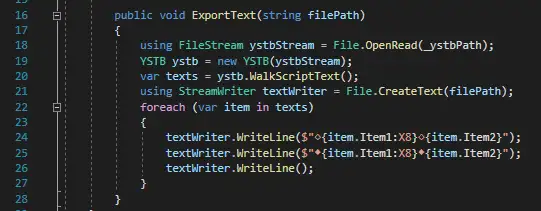
得到: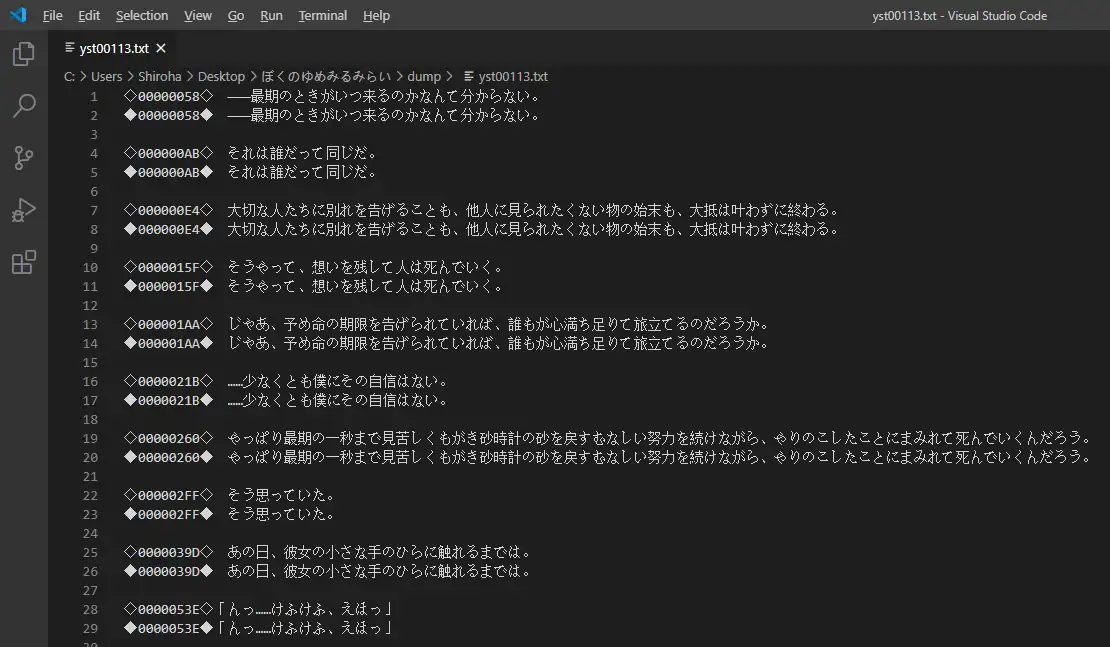
现在就可以把文本发给翻译鸽了
五、汉化
经过翻译鸽不懈努力(新建文件夹(1)(2)(3)(bushi)) 我们终于拿到翻译好的文本了。那么要怎么把han化文本塞回去呢?
回到 VM_FN_WORD 这个函数,既然它是从DataSection里把游戏文本复制出来的,那么我们能不能从这里,把文本偷换掉呢?
理论上是可以的。那么怎么做呢?那当然是写Hook啦。转到反汇编看看这个Q_memcpy
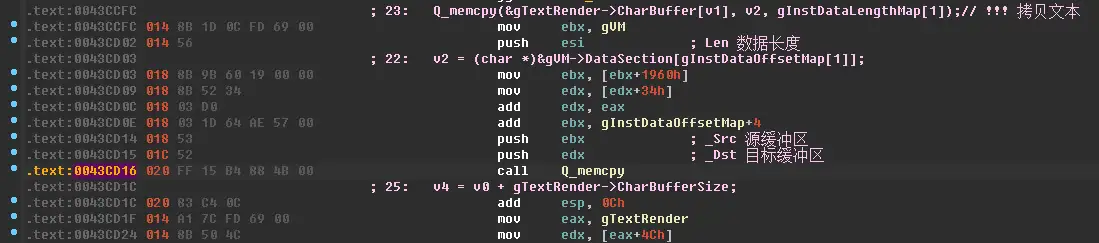
在 call Q_memcpy 这里跳转到我们的补丁(DLL)代码去
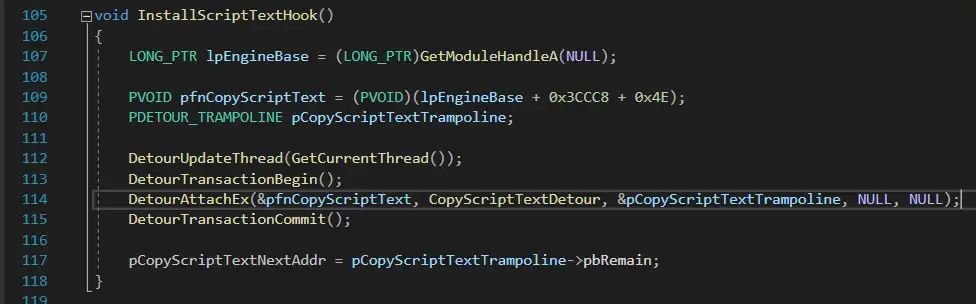
这里就不自己手动汇编了,利用Detours即可完成(真香)。Hook完之后,代码就变成了这样:
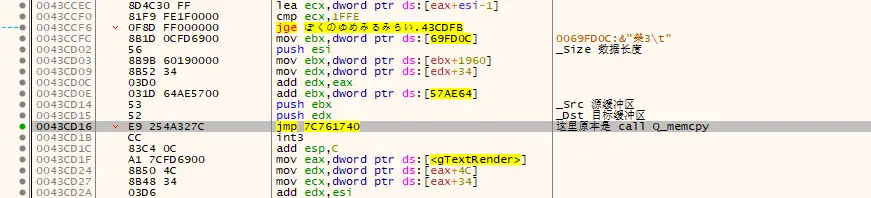
然后这里是Hook代码:

这里调用了CopyScriptText这个函数来把新的文本复制进去。
复制文本进去后,EBX和ESI寄存器的值也要改掉,因为接下来的函数代码里要用到这两个寄存器的值。
注意看下图的v0和v2
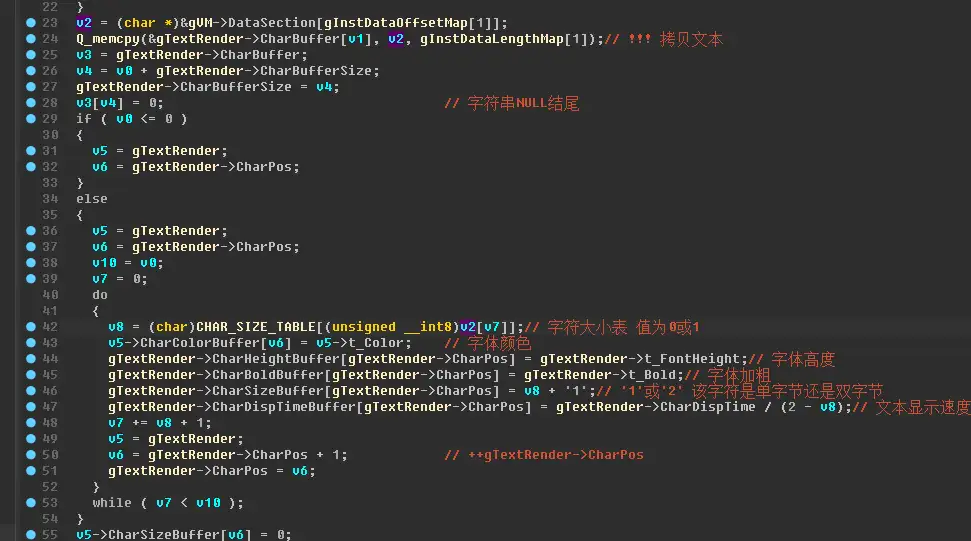
由于CopyScriptText是4个参数的,所以又PUSH了一个参数进去。
原本就已经PUSH了3个参数。所以调用完CopyScriptText之后,先平一下栈。
然后从返回值和参数中拿到新文本的内存地址和数据长度。最后JMP回原函数继续执行
跳回到 43CD1C 这里,add esp, c 是把上面 push 的三个参数平了,那么文本就已经偷换成功了

五、汉化(2)
文本换掉之后,还要处理字体和字符边界检查的问题,这个版本的yu-ris引擎处理起来都比较简单。
这里简单说一下:
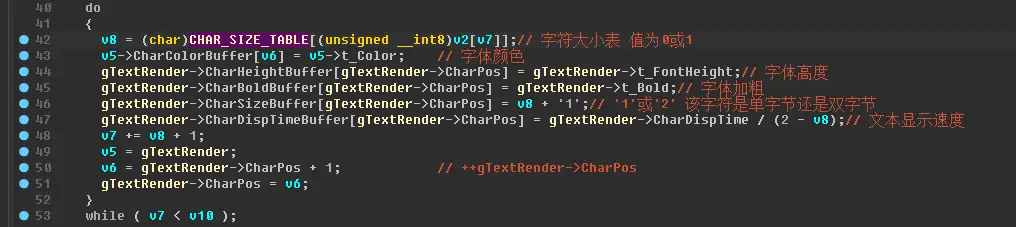
众所周知,ANSI编码的情况下,一个中文字(GBK编码)至少2个字节。
看上图的 CHAR_SIZE_TABLE 这个东西,它是一个数组,表示每个字的大小-1
假设这里有个中文字的数据(2字节):
data[0] = 0xa4;
data[1] = 0x12;
那么引擎即可根据 CHAR_SIZE_TABLE [ data[0] ] 得知这个字是单字节还是双字节
这个表里的值只有0和1,0表示字的字节数为1字节,1表示字的字节数为2字节
所以必须要修改这个表,才能支持所有的中文字
代码如下:
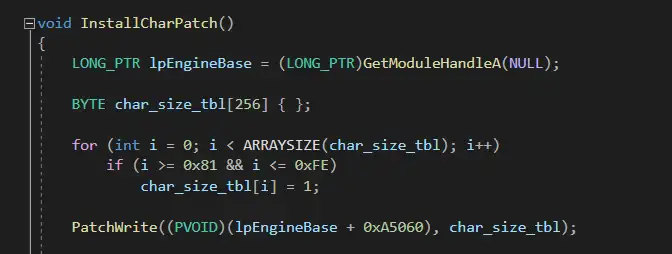
GBK编码中的所有中文字的第一个字节的值范围都在 0x81-0xFE 内,所以把这个范围内的值改为1即可。
然后字体也需要处理一下,查看所有与字体相关的API调用,
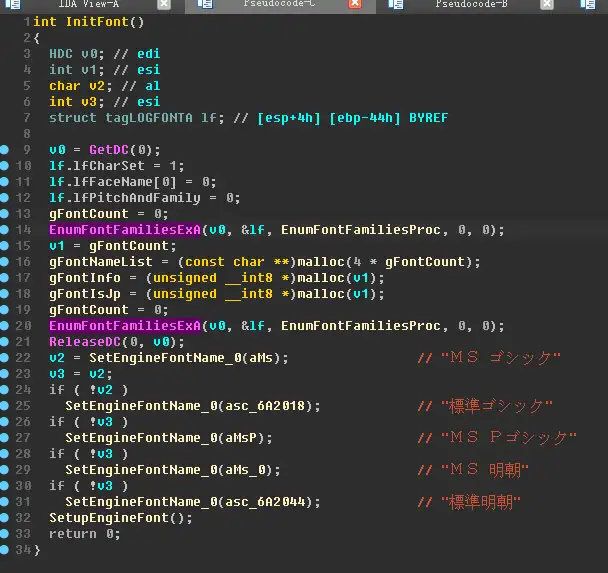
这里检查了一下发现EnumFontFamiliesExA的参数LONGFONTA中的lfCharSet为DEFAULT_CHARSET(1)
所以这里不需要修改。接着找到 SetupEngineFont 里去看看
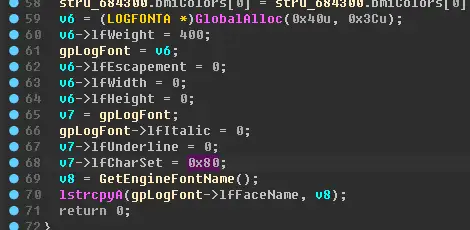
这里发现它把LOGFONT.lfCharSet改为了SHIFTJIS_CHARSET(0x80) 所以这里就要改掉了
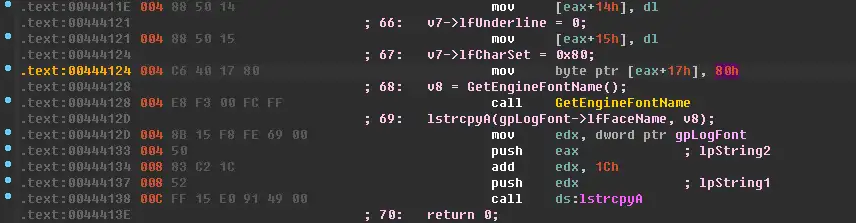
直接把值改掉即可
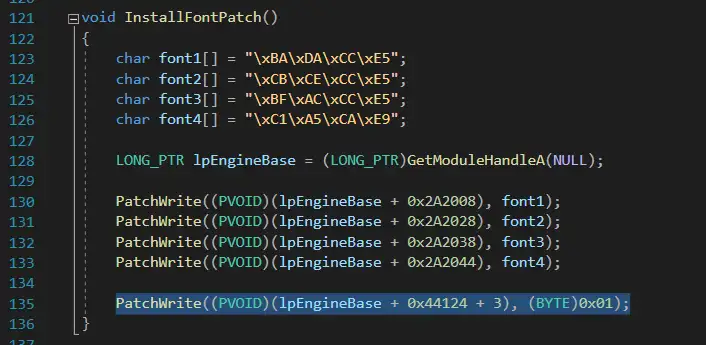
上图中还有修改字体名的代码,此外稍作检查,发现没有其它与字体相关的代码了。
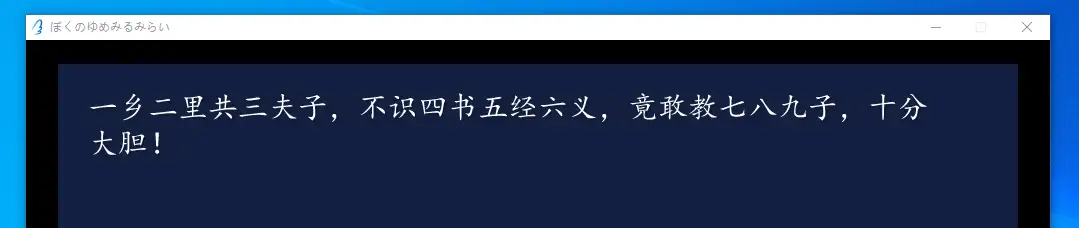
替换文本成功,字体修改成功。
另外:关于图片之类的修改,如果不想封包,直接 Hook FS_ReadFile 即可
本文转自贴吧 /p/7187053034 已获得原作者 展鸿丶 同意

